13 KiB
| layout | title |
|---|---|
| page | RPC Protocol |
RPC Protocol
Introduction
Time Travel! (Promise Pipelining)
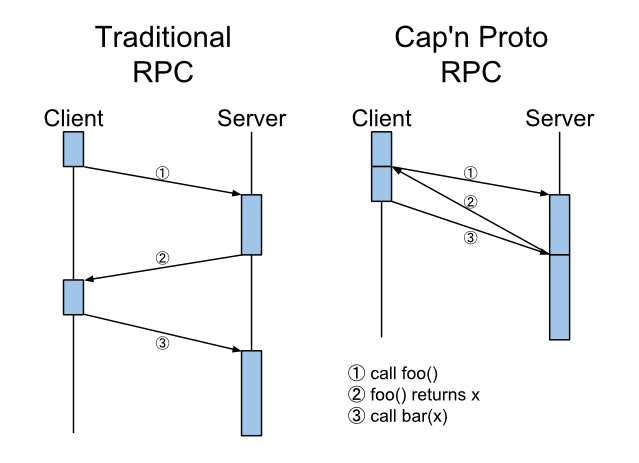
Cap'n Proto RPC employs TIME TRAVEL! The results of an RPC call are returned to the client instantly, before the server even receives the initial request!
There is, of course, a catch: The results can only be used as part of a new request sent to the same server. If you want to use the results for anything else, you must wait.
This is useful, however: Say that, as in the picture, you want to call foo(), then call bar()
on its result, i.e. bar(foo()). Or -- as is very common in object-oriented programming -- you
want to call a method on the result of another call, i.e. foo().bar(). With any traditional RPC
system, this will require two network round trips. With Cap'n Proto, it takes only one. In fact,
you can chain any number of such calls together -- with diamond dependencies and everything -- and
Cap'n Proto will collapse them all into one round trip.
By now you can probably imagine how it works: if you execute bar(foo()), the client sends two
messages to the server, one saying "Please execute foo()", and a second saying "Please execute
bar() on the result of the first call". These messages can be sent together -- there's no need
to wait for the first call to actually return.
To make programming to this model easy, in your code, each call returns a "promise". Promises
work much like JavaScript promises or promises/futures in other languages: the promise is returned
immediately, but you must later call wait() on it, or call then() to register an asynchronous
callback.
However, Cap'n Proto promises support an additional feature: pipelining. The promise actually has methods corresponding to whatever methods the final result would have, except that these methods may only be used for the purpose of calling back to the server. Moreover, a pipelined promise can be used in the parameters to another call without waiting.
But isn't that just syntax sugar?
OK, fair enough. In a traditional RPC system, we might solve our problem by introducing a new
method foobar() which combines foo() and bar(). Now we've eliminated the round trip, without
inventing a whole new RPC protocol.
The problem is, this kind of arbitrary combining of orthogonal features quickly turns elegant object-oriented protocols into ad-hoc messes.
For example, consider the following interface:
{% highlight capnp %}
A happy, object-oriented interface!
interface Node {}
interface Directory extends(Node) { list @0 () -> (list: List(Entry)); struct Entry { name @0 :Text; file @1 :Node; }
create @1 (name :Text) -> (node :Node); open @2 (name :Text) -> (node :Node); delete @3 (name :Text); link @4 (name :Text, node :Node); }
interface File extends(Node) { size @0 () -> (size: UInt64); read @1 (startAt :UInt64, amount :UInt64) -> (data: Data); write @2 (startAt :UInt64, data :Data); truncate @3 (size :UInt64); } {% endhighlight %}
This is a very clean interface for interacting with a file system. But say you are using this
interface over a satellite link with 1000ms latency. Now you have a problem: simply reading the
file foo in directory bar takes four round trips!
{% highlight python %}
pseudocode
bar = root.open("bar"); # 1 foo = bar.open("foo"); # 2 size = foo.size(); # 3 data = foo.read(0, size); # 4
The above is four calls but takes only one network
round trip with Cap'n Proto!
{% endhighlight %}
In such a high-latency scenario, making your interface elegant is simply not worth 4x the latency. So now you're going to change it. You'll probably do something like:
- Introduce a notion of path strings, so that you can specify "foo/bar" rather than make two separate calls.
- Merge the
FileandDirectoryinterfaces into a singleFilesysteminterface, where every call takes a path as an argument.
{% highlight capnp %}
A sad, singleton-ish interface.
interface Filesystem { list @0 (path :Text) -> (list :List(Text)); create @1 (path :Text, data :Data); delete @2 (path :Text); link @3 (path :Text, target :Text);
fileSize @4 (path :Text) -> (size: UInt64); read @5 (path :Text, startAt :UInt64, amount :UInt64) -> (data :Data); readAll @6 (path :Text) -> (data: Data); write @7 (path :Text, startAt :UInt64, data :Data); truncate @8 (path :Text, size :UInt64); } {% endhighlight %}
We've now solved our latency problem... but at what cost?
- We now have to implement path string manipulation, which is always a headache.
- If someone wants to perform multiple operations on a file or directory, we now either have to re-allocate resources for every call or we have to implement some sort of cache, which tends to be complicated and error-prone.
- We can no longer give someone a specific
Fileor aDirectory-- we have to give them aFilesystemand a path.- But what if they are buggy and have hard-coded some path other than the one we specified?
- Or what if we don't trust them, and we really want them to access only one particular
FileorDirectoryand not have permission to anything else. Now we have to implement authentication and authorization systems! Arrgghh!
Essentially, in our quest to avoid latency, we've resorted to using a singleton-ish design, and singletons are evil.
Promise Pipelining solves all of this!
With pipelining, our 4-step example can be automatically reduced to a single round trip with no need to change our interface at all. We keep our simple, elegant, singleton-free interface, we don't have to implement path strings, caching, authentication, or authorization, and yet everything performs as well as we can possibly hope for.
Example code
The calculator example uses promise pipelining. Take a look at the client side in particular.
Distributed Objects
As you've noticed by now, Cap'n Proto RPC is a distributed object protocol. Interface references -- or, as we more commonly call them, capabilities -- are a first-class type. You can pass a capability as a parameter to a method or embed it in a struct or list. This is a huge difference from many modern RPC-over-HTTP protocols that only let you address global URLs, or other RPC systems like Protocol Buffers and Thrift that only let you address singleton objects exported at startup. The ability to dynamically introduce new objects and pass around references to them allows you to use the same design patterns over the network that you use locally in object-oriented programming languages. Many kinds of interactions become vastly easier to express given the richer vocabulary.
Didn't CORBA prove this doesn't work?
No!
CORBA failed for many reasons, with the usual problems of design-by-committee being a big one.
However, the biggest reason for CORBA's failure is that it tried to make remote calls look the same as local calls. Cap'n Proto does NOT do this -- remote calls have a different kind of API involving promises, and accounts for the presence of a network introducing latency and unreliability.
As shown above, promise pipelining is absolutely critical to making object-oriented interfaces work in the presence of latency. If remote calls look the same as local calls, there is no opportunity to introduce promise pipelining, and latency is inevitable. Any distributed object protocol which does not support promise pipelining cannot -- and should not -- succeed. Thus the failure of CORBA (and DCOM, etc.) was inevitable, but Cap'n Proto is different.
Handling disconnects
Networks are unreliable. Occasionally, connections will be lost. When this happens, all capabilities (object references) served by the connection will become disconnected. Any further calls addressed to these capabilities will throw "disconnected" exceptions. When this happens, the client will need to create a new connection and try again. All Cap'n Proto applications with long-running connections (and probably short-running ones too) should be prepared to catch "disconnected" exceptions and respond appropriately.
On the server side, when all references to an object have been "dropped" (either because the
clients explicitly dropped them or because they became disconnected), the object will be closed
(in C++, the destructor is called; in GC'd languages, a close() method is called). This allows
servers to easily allocate per-client resources without having to clean up on a timeout or risk
leaking memory.
Security
Cap'n Proto interface references are capabilities. That is, they both designate an object to call and confer permission to call it. When a new object is created, only the creator is initially able to call it. When the object is passed over a network connection, the receiver gains permission to make calls -- but no one else does. In fact, it is impossible for others to access the capability without consent of either the host or the receiver because the host only assigns it an ID specific to the connection over which it was sent.
Capability-based design patterns -- which largely boil down to object-oriented design patterns -- work great with Cap'n Proto. Such patterns tend to be much more adaptable than traditional ACL-based security, making it easy to keep security tight and avoid confused-deputy attacks while minimizing pain for legitimate users. That said, you can of course implement ACLs or any other pattern on top of capabilities.
For an extended discussion of what capabilities are and why they are often easier and more powerful than ACLs, see Mark Miller's "An Ode to the Granovetter Diagram" and Capability Myths Demolished.
Protocol Features
Cap'n Proto's RPC protocol has the following notable features. Since the protocol is complicated, the feature set has been divided into numbered "levels", so that implementations may declare which features they have covered by advertising a level number.
- Level 1: Object references and promise pipelining, as described above.
- Level 2: Persistent capabilities. You may request to "save" a capability, receiving a persistent token which can be used to "restore" it in the future (on a new connection). Not all capabilities can be saved; the host app must implement support for it. Building this into the protocol makes it possible for a Cap'n-Proto-based data store to transparently save structures containing capabilities without knowledge of the particular capability types or the application built on them, as well as potentially enabling more powerful analysis and visualization of stored data.
- Level 3: Three-way interactions. A network of Cap'n Proto vats (nodes) can pass object references to each other and automatically form direct connections as needed. For instance, if Alice (on machine A) sends Bob (on machine B) a reference to Carol (on machine C), then machine B will form a new connection to machine C so that Bob can call Carol directly without proxying through machine A.
- Level 4: Reference equality / joining. If you receive a set of capabilities from different parties which should all point to the same underlying objects, you can verify securely that they in fact do. This is subtle, but enables many security patterns that rely on one party being able to verify that two or more other parties agree on something (imagine a digital escrow agent). See E's page on equality.
Encryption
At this time, Cap'n Proto does not specify an encryption scheme, but as it is a simple byte stream protocol, it can easily be layered on top of SSL/TLS or other such protocols.
Specification
The Cap'n Proto RPC protocol is defined in terms of Cap'n Proto serialization schemas. The documentation is inline. See rpc.capnp.
Cap'n Proto's RPC protocol is based heavily on CapTP, the distributed capability protocol used by the E programming language. Lots of useful material for understanding capabilities can be found at those links.
The protocol is complex, but the functionality it supports is conceptually simple. Just as TCP is a complex protocol that implements the simple concept of a byte stream, Cap'n Proto RPC is a complex protocol that implements the simple concept of objects with callable methods.